Recently, significant advancements have been made in 3D generative models, however training these models across diverse domains is challenging and requires an enormous amount of training data and knowledge of pose distribution.
Text-guided domain adaptation methods have allowed the generator to be adapted to the target domains using text prompts, thereby obviating the need for assembling numerous data. Recently, DATID-3D presents impressive quality of view consistent images in text-guided domain, preserving diversity in text by leveraging text-to-image diffusion models. However, adapting 3D generators to domains with significant domain gaps from the source domain still remains challenging due to issues in current text-to-image diffusion models. These issues include: 1) shape-pose trade-off in diffusion-based translation, 2) pose bias, and 3) instance bias in the target domain, resulting in inferior 3D shapes, low text-image correspondence, and low intra-domain diversity in the generated samples.
To address these issues, we propose a novel pipeline called PODIA-3D, which uses pose-preserved text-to-image diffusion-based domain adaptation for 3D generative models.
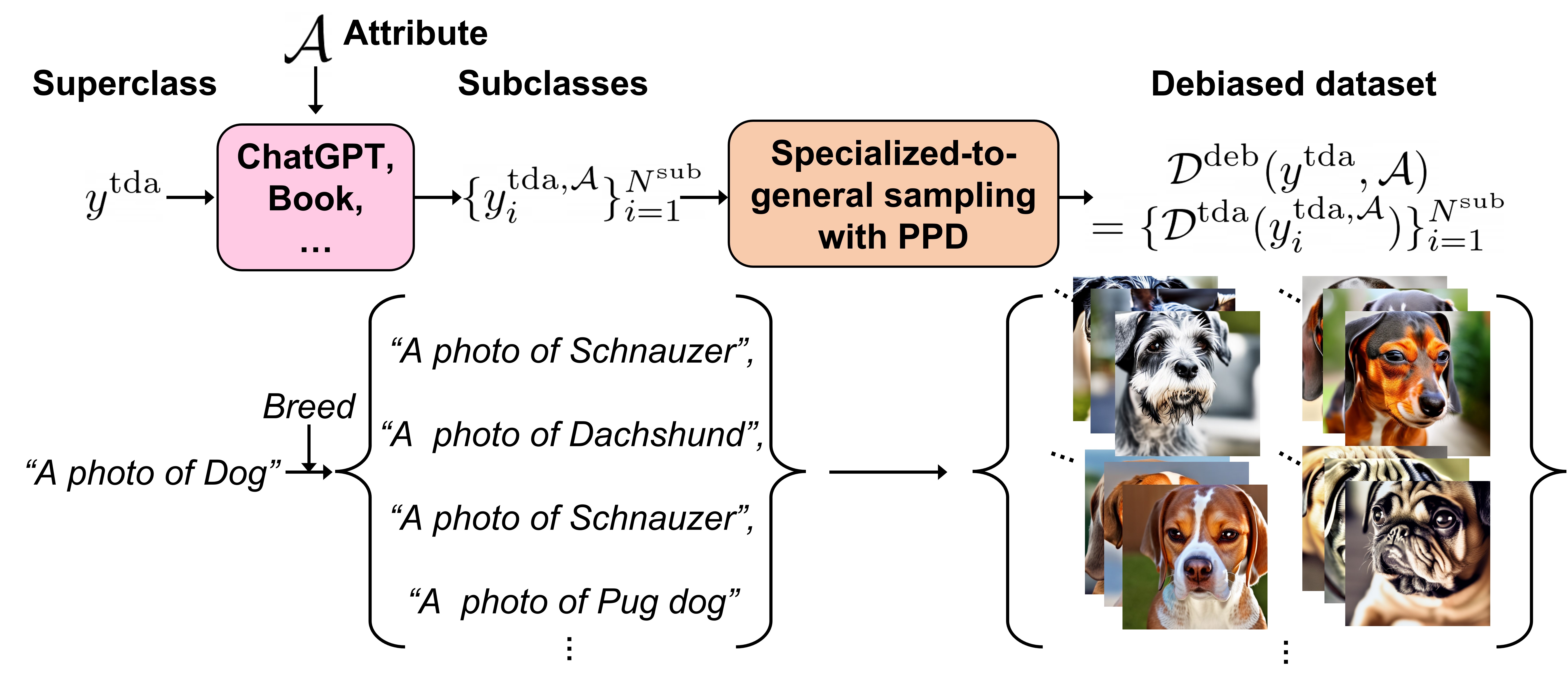
We construct a pose-preserved text-to-image diffusion model that allows the use of extremely high-level noise for significant domain changes. We also propose specialized-to-general sampling strategies to improve the details of the generated samples. Moreover, to overcome the instance bias, we introduce a text-guided debiasing method that improves intra-domain diversity. Consequently, our method successfully adapts 3D generators across significant domain gaps, producing excellent text-image correspondence and 3D shapes, while the baselines mostly fail. Our qualitative results and user study demonstrates that our approach outperforms existing 3D text-guided domain adaptation methods in terms of text-image correspondence, realism, diversity of rendered images, and sense of depth of 3D shapes in the generated samples.